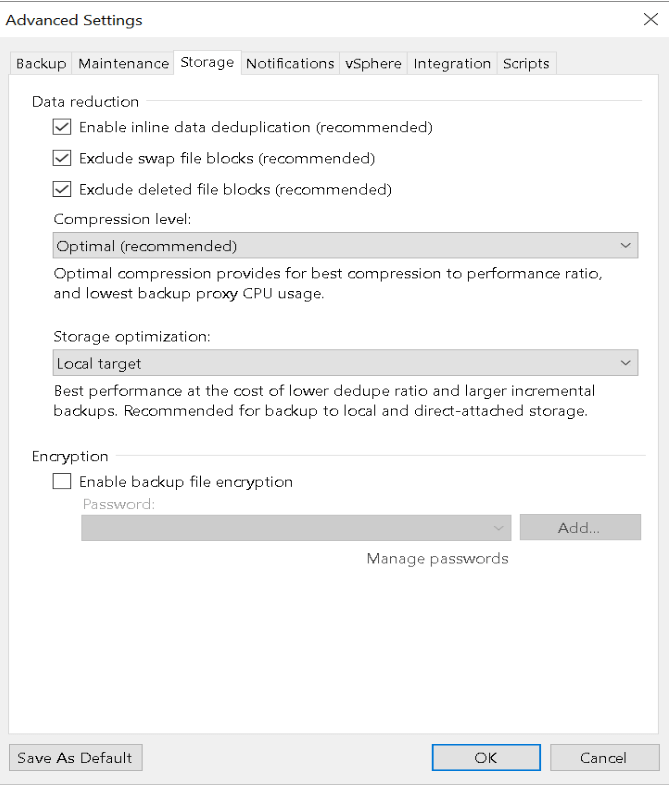
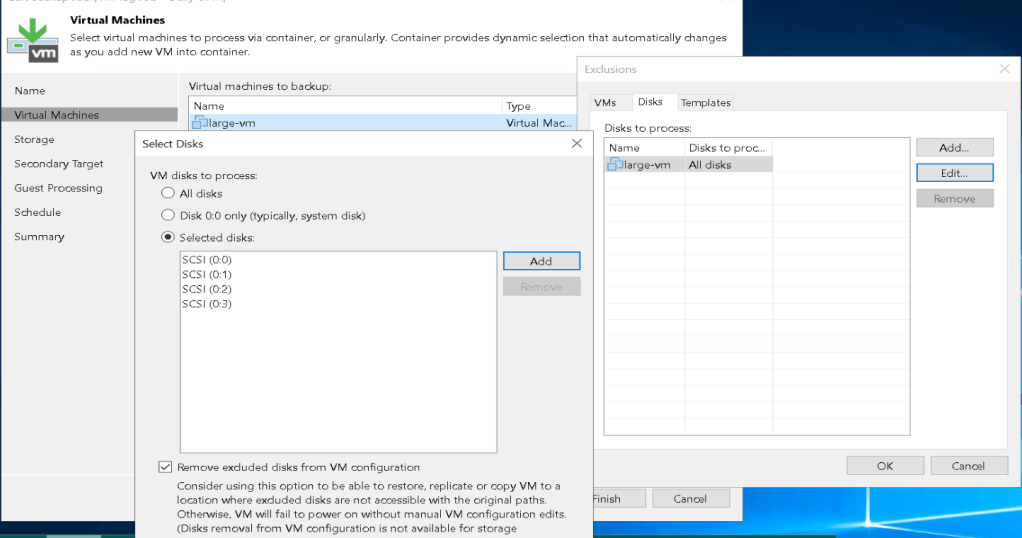
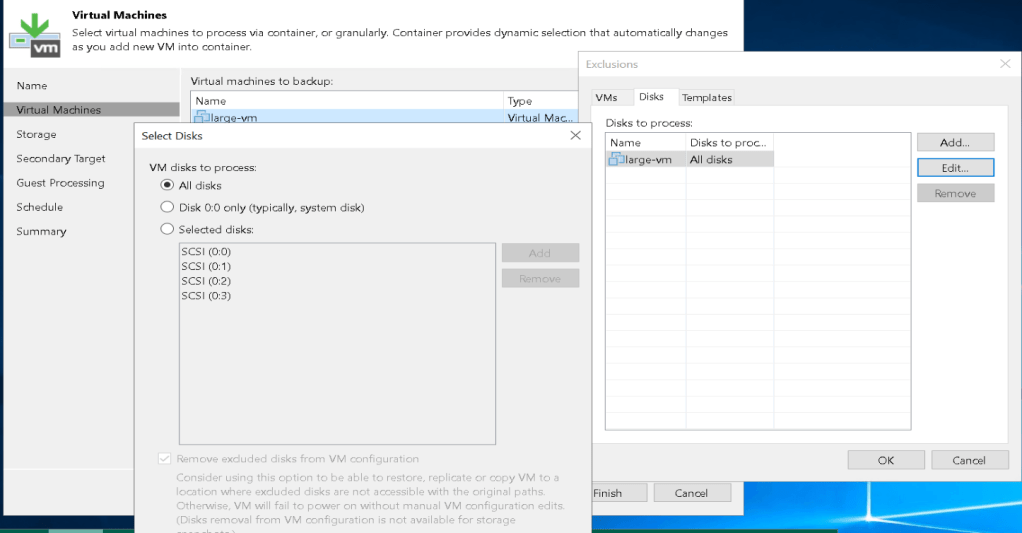
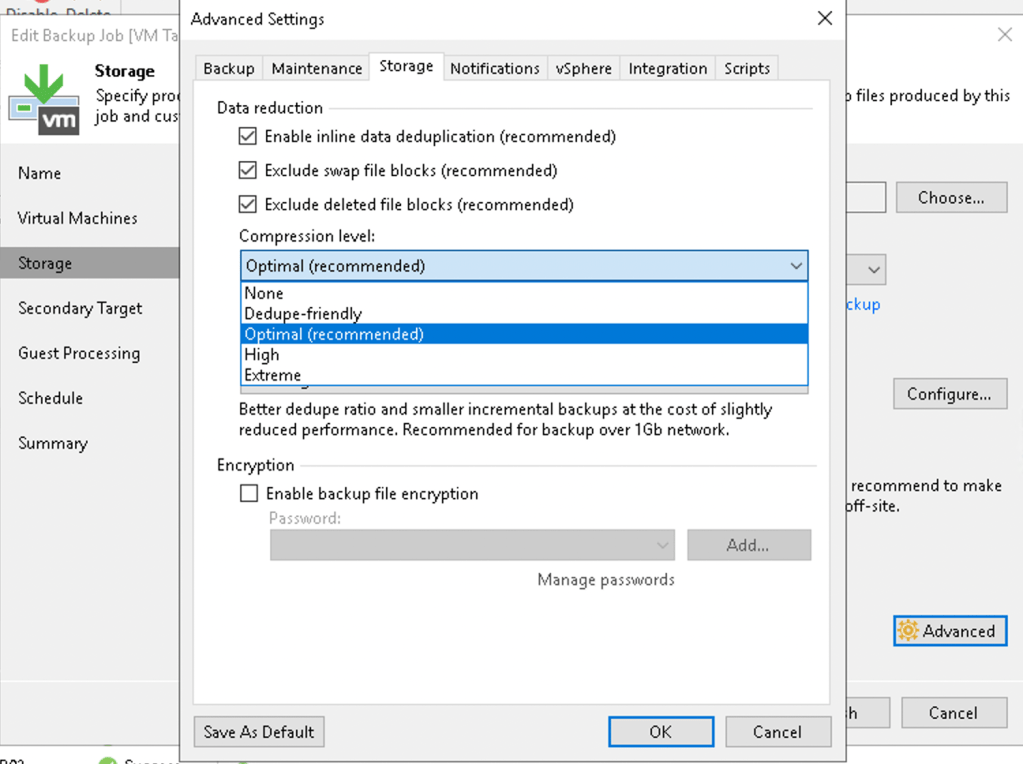
Rubrik supports doing SAN-integrated snapshots to perform backups of virtual machines similar to other backup products. My experience with Rubrik is that it seems to perform each backup as an individual task rather than trying to perform all the required operations on a target at the same time. For example, if you have an SLA policy targeting a SQL database/instance it will run as a separate process to the VM image based backup of that SQL server.
This seems to extend to how it performs backups with storage integrated snapshots, it doesn’t do any analysis of the VMs on each datastore to target multiple VM backups with the same storage snapshot. This seems to be the reason that Rubrik recommends using the storage integrated snapshot feature for specific workloads only.
For one of my recent clients, I quickly wrote the below script for enabling/disabling storage snapshots using their PureStorage FlashArray across their entire VM environment. To use it, you need to configure an API token for Rubrik and then run it against the target Rubrik Brik local API endpoint.
$rubrikURL = "https://rubrik.fqdn.internal/api/" # update me
# Get the API Token for the api requests
if ($token -eq $null) {
$token = read-host -Prompt "API Token for $rubrikURL"
}
# Connect to Rubrik and get a list of virtual machines
$endpoint = "v1/vmware/vm"
$uri = "$rubrikURL$endpoint"
$data = Invoke-WebRequest -Method Get -Headers @{ "accept" = "application/json"; "Authorization" = "Bearer $token" } -uri "$uri"
$vmlist = $data.content | convertfrom-json | select-object -ExpandProperty data
# Get more details about each VM
$vmdetails = @()
foreach ($vm in $vmlist | select-object -first 2) {
$vmid = $vm | select-object -ExpandProperty id
$endpoint = "v1/vmware/vm/$vmid"
$uri = "$rubrikURL$endpoint"
$data = Invoke-WebRequest -Method Get -Headers @{ "accept" = "application/json"; "Authorization" = "Bearer $token" } -uri "$uri"
$detail = $data.content | convertfrom-json
$vmdetails += $detail
}
# Detail the VMs and VMs that require updates
write-host "VM Details:"
$vmdetails | ft id,name,isArrayIntegrationPossible,isArrayIntegrationEnabled
write-host "VMs capable of array integration (but not yet enabled):"
$vmsrequiringupdate = $vmdetails | where-object { $_.isArrayIntegrationEnabled -eq $false -and $_.isArrayIntegrationPossible -eq $true}
$vmsrequiringupdate | ft id,name,isArrayIntegrationPossible,isArrayIntegrationEnabled
# 'Patch' each VM to enable array integration
foreach ($vmdetail in $vmsrequiringupdate ) {
$vmid = $vmdetail.id
$endpoint = "v1/vmware/vm/$vmid"
$uri = [uri]::EscapeUriString("$rubrikURL$endpoint")
write-host "Processing $($vmdetail.name) with id $vmid at $uri " -NoNewline
$patchdetails = @{ "isArrayIntegrationEnabled" = $true } | ConvertTo-Json -Compress # change to false to disable storage snapshots
# Perform the patch request
$data = Invoke-WebRequest -Method "Patch" -Headers @{ "content-type" = "application/json"; "accept" = "application/json"; "Authorization" = "Bearer $token" } -uri $uri -body $patchdetails -ContentType "application/json"
if ($data.StatusCode -eq 200) {
write-host "(Status $($data.StatusCode))" -ForegroundColor Green
} else {
write-host "(Status $($data.StatusCode))" -ForegroundColor Red
}
}